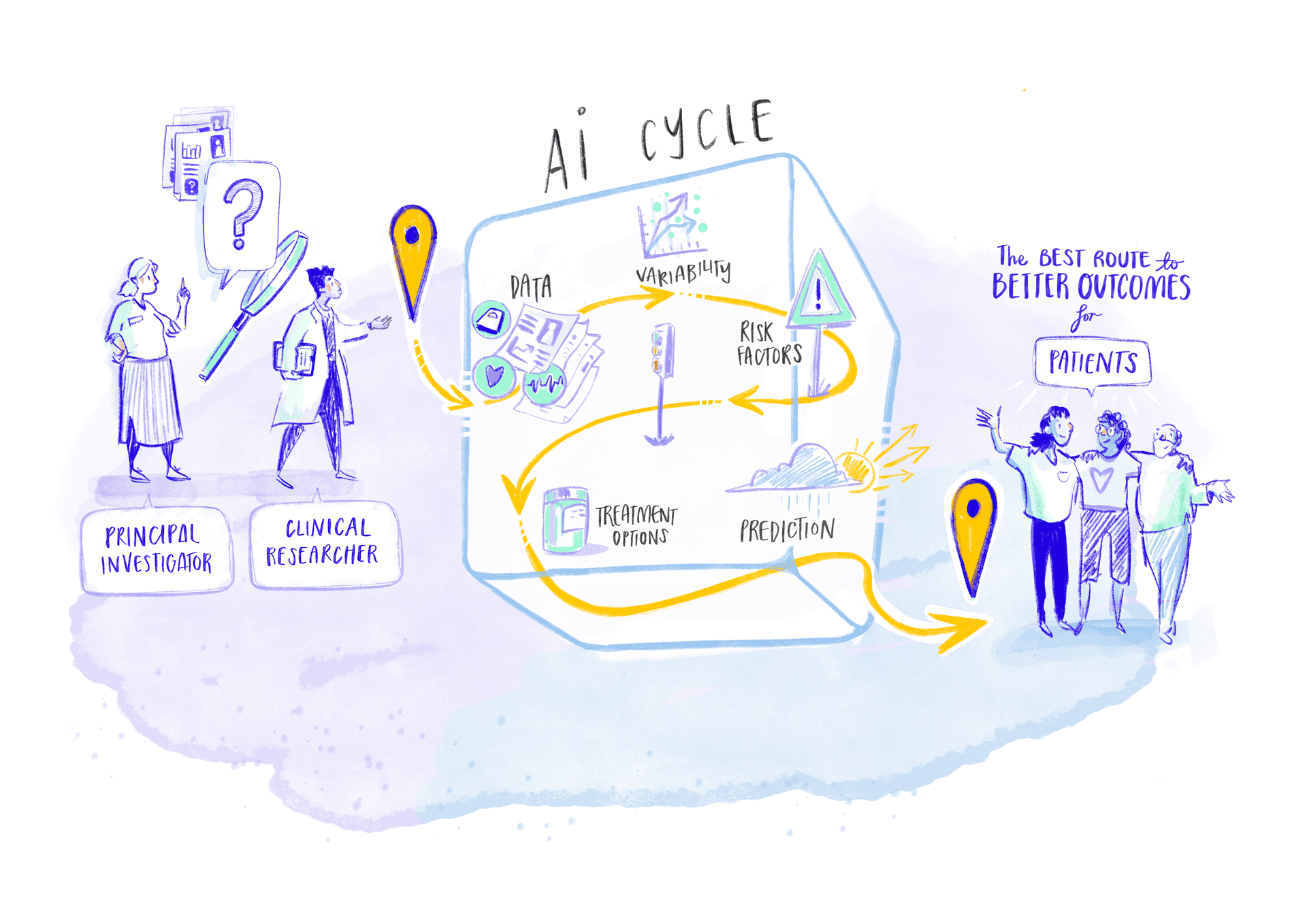
AI has changed the way we travel, communicate and work, and even how entire industries operate, with the healthcare sector now standing at the forefront of this transformation. In addition to personalising treatments, automating clinical workflows, implementing predictive tools, enabling virtual healthcare devices, AI helps professionals make earlier and better-informed decisions by processing immense volumes of data, ultimately leading to better outcomes for patients. UMBRELLA is harnessing this transformative power of AI to enhance stroke prevention, diagnosis and treatment.
Welcome to the AI Journey
This means that the model follows the most efficient route or mathematical “path” to reach a same destination. The AI model applies these learned patterns to new data to produce results, such as identifying something or predicting what might happen next. To create and refine these AI models, some important steps need to be taken.
In UMBRELLA, we are developing various AI models to improve stroke care.
AI lifecycle
in UMBRELLA
Explore each step of UMBRELLA's AI journey through this interactive diagram
Guided by experts every step of the way
From the initial concept to the final result, every step of the AI journey is overseen by an expert. Principal Investigators (PIs) and other researchers, data scientists, administrators, doctors and other healthcare professionals, Information Technology (IT) specialists, patients and independent bodies such ethics committees and regulators are involved in the process. Human specialists continually monitor, review and steer every stage of the development and application of AI algorithms, ensuring that both the process and the results remain faithful to the data and genuinely serve the interests of patients.


STEP 1 - DATA SEARCH
It’s all about the data!
AI relies on huge quantities of data to work effectively. It is essential that this data is not only abundant but also high quality, diverse and representative for AI models in healthcare to operate properly, meaning that it should include many different datasets and reflect the real population the AI will be used on. If the data is incomplete or biased, that is, if it does not fairly represent all groups or contains systematic errors the AI will learn wrong patterns and may give unreliable results.
What types of data are used by AI systems?
AI functions on data that is routinely collected during patient care, such as blood tests or biomarkers that help to understand health conditions. Increasingly, other sources of data providing rich information are being used as well. These include data from scientific research, notes written by doctors during check-ups, details from medical history reports, images from medical scans like electroencephalograms taken in ambulances, and even feedback from patients about their experiences and health outcomes (known as PREMs and PROMs). By bringing together data from diverse sources, AI can perform more accurate analysis and make better predictions, supporting healthcare professionals in making decisions and improving patient care.
The specific objectives of an AI model, such as estimating the risk of recurring strokes or predicting treatment response, determine the type of data required. This is outlined by the Principal Investigator, who is the researcher leading and overseeing the entire research project. The PI also decides which data the investigation will focus on. For instance, for stroke it could be useful to use brain scans, emergency room records, patient age or symptoms. If the goal is to identify stroke, the chosen data should reflect information that helps recognise stroke signs quickly and accurately.
Meet the Pls in Umbrella

Name Surname
TBC

STEP 2 - DATA COLLECTION
Gathering data from various sources and storing it safely in hospitals
Typical data sources in Umbrella are:
Clinical systems like Electronic
Health Records (EHRs), hospital
information systems and stroke registries providing comprehensive patient histories
and treatment outcomes.
Research databases consisting
of data collected previously, for example in randomised controlled trials and cohort studies.
Medical imaging such as CT
and MRI scans and angiograms that capture critical brain and vascular information for stroke diagnosis and treatment planning.
Medical devices, especially point of care technologies like EEG-based stroke detection devices that monitor brain activity patterns to identify early warning signs and enable rapid intervention.
Mobile applications like smartphone apps that track patient movement patterns, reported outcomes, medication adherence and enable real-time symptom reporting for stroke survivors.
How is data collected and stored in UMBRELLA?
There are seven renowned hospitals participating in UMBRELLA. Each hospital collects and stores its own data on their local servers. For security reasons, this sensitive data never leaves the hospital; it is not shared externally to ensure security and full patient privacy protection.

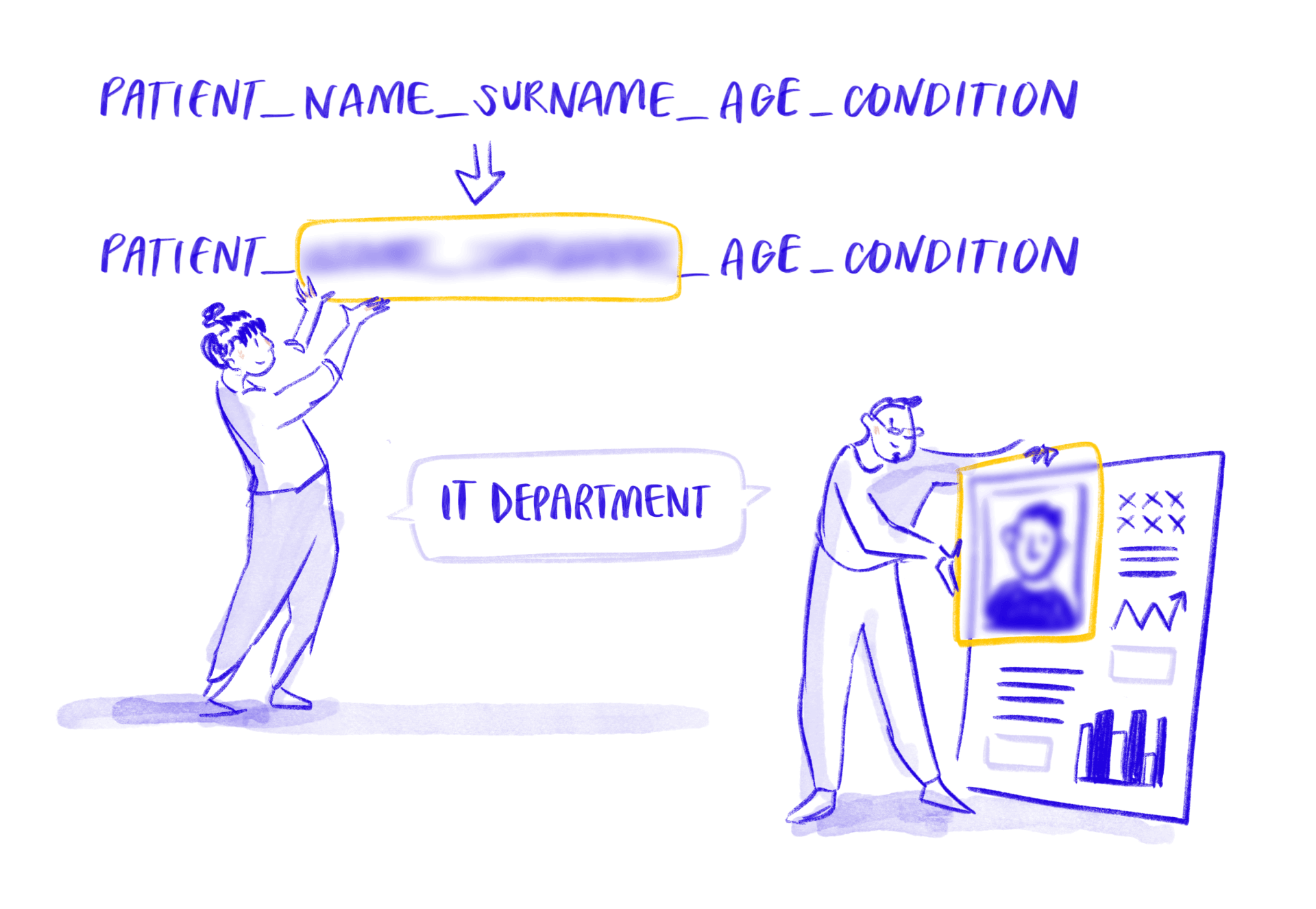
How is patient privacy protected?
Through pseudonymisation. This is a process used to protect patient privacy by replacing personal information, such as names or ID numbers, with artificial identifiers or codes. This means that healthcare professionals and researchers can still use the data for important work, like improving treatments or understanding health trends, but cannot directly identify individual patients from the information alone.
Name Surname
TBC
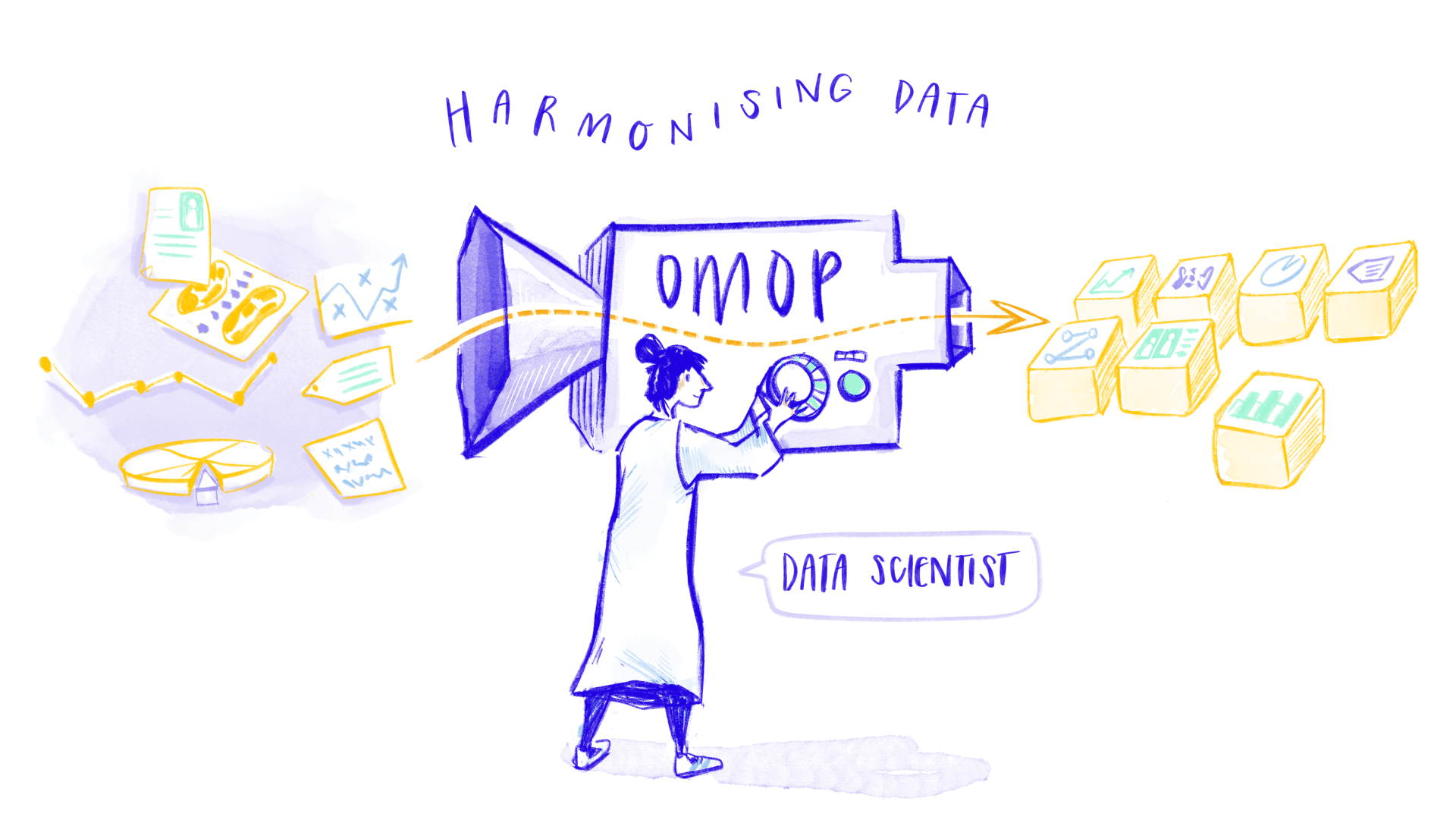
STEP 3 - PREPARING AND LOCALLY MERGING DATA
Getting data to speak the same language and loading it into protected systems
This phase involves the extraction, transformation and loading of data (ETL). This is the process of pulling data from various places (like apps or databases), standardising it and moving it into one central spot (like a data warehouse) for analysis, creating a single source for research insights.
Before AI models can effectively analyse different types of stroke data from different sources, these data sets need to be standardised and harmonised.
The harmonisation is performed using an Observational Medical Outcomes Partnership (OMOP) approach – a common data model that acts as a universal language for health data, making information from many different sources understandable and usable together. A ‘translator’ is created to ensure that all data speaks this language. Imagine you’re traveling to a country with different electrical outlets. Your devices won’t work unless you use a travel adapter that lets you plug them into the local sockets. In the same way, OMOP is an adapter that standardises all kinds of health data, so that it can “plug in” and be used seamlessly in one shared system.
Labelling the data is crucial for the training and evaluation of the AI models. Creating accurate labels is not easy and it is a key step of the UMBRELLA project.
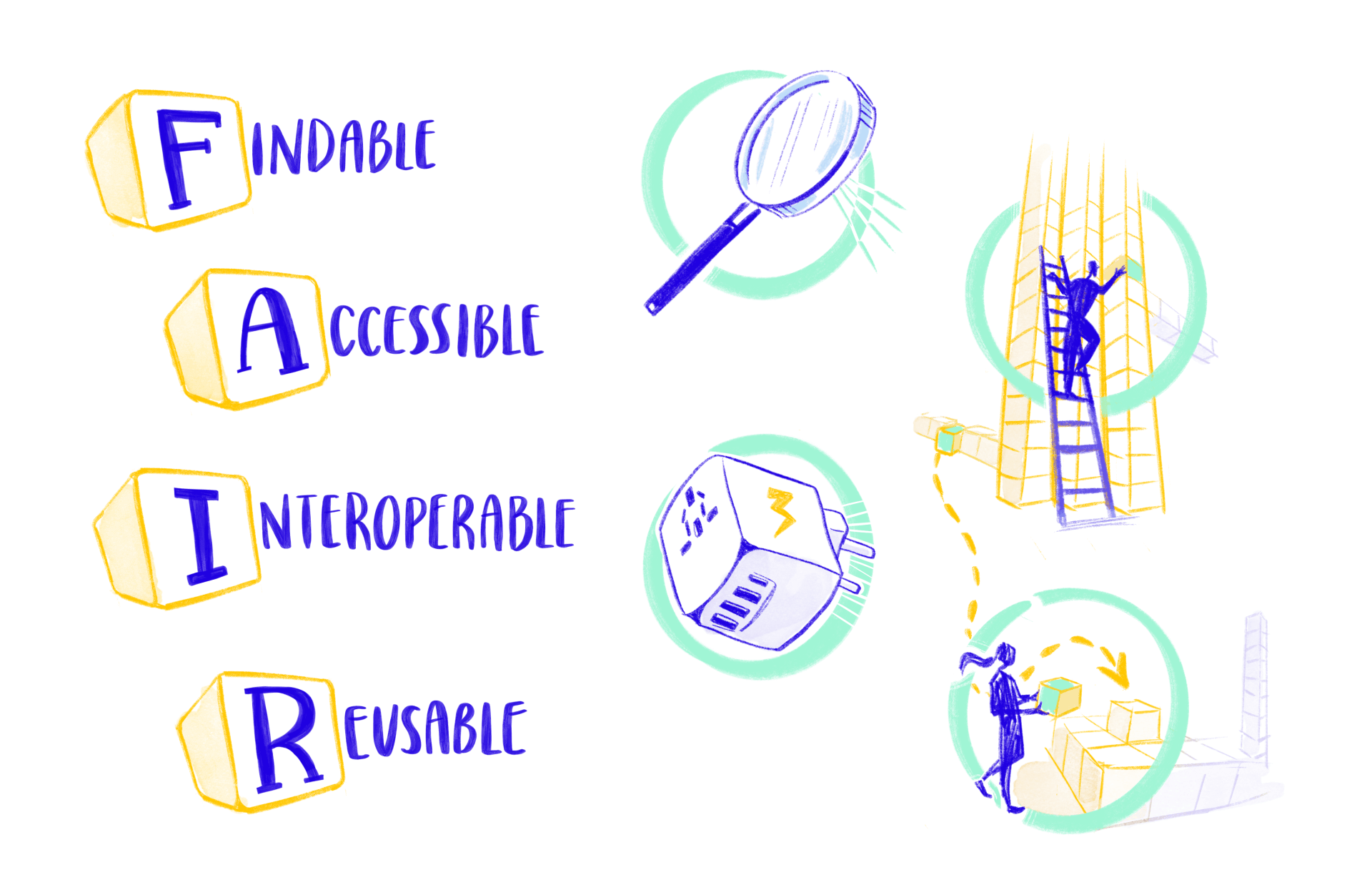
The concept of FAIRification is key in this phase
This is the process of making data Findable, Accessible, Interoperable and Reusable (FAIR) for both humans and machines, especially in research. Let’s break down each part of these concepts.
Findable
Imagine you’re looking for a book in a library. If books are labelled and listed in a catalogue, it’s much easier to find the one you need. In the same way, data should be organised and labelled so that anyone, whether a person or a computer, can easily search for and locate it.
Accessible
Once you’ve found the book in the library, you need to be able to take it off the shelf and read it. With data, accessibility means that people and systems can retrieve and use the information they’ve found. There might be some rules about who can see or borrow the book, just like with data the book may have permissions or restrictions.
Interoperable
Using the analogy of universal adapters for electronic devices, interoperability ensures that data from various sources, whether from hospitals, research labs or patients’ smartphones, can “plug in” and work together. This is key for combining data to get a fuller picture.
Reusable
Think of data reusability like a set of well-labelled building blocks. If each block is clearly marked and standardised, anyone can pick them up and build something new, whether that’s following the original instructions or creating an entirely different structure. In the same way, reusable data is organised and described so that others can understand and use it for all sorts of new research or analysis, not just what it was first intended for.
Name Surname
TBC
Expert in rehabiliation medicine and prediction models
STEP 4 - ANALYSIS AND TRAINING
Exploring patterns and relationships to develop AI Models
Traditionally, AI models in healthcare have been trained using a centralised approach, where data from multiple hospitals and sources is transferred to a single server for analysis. While this can simplify data management and model development, it comes with important drawbacks.
Centralised systems are more vulnerable to privacy breaches and cyberattacks, and even pseudonymised data can sometimes be re‑identified when combined with other information. They also raise legal and ethical concerns, as moving sensitive patient data between institutions can conflict with data protection laws and reduce trust. In addition, hospitals lose a degree of autonomy, as data governance and control are shifted to a central infrastructure managed by an external provider.
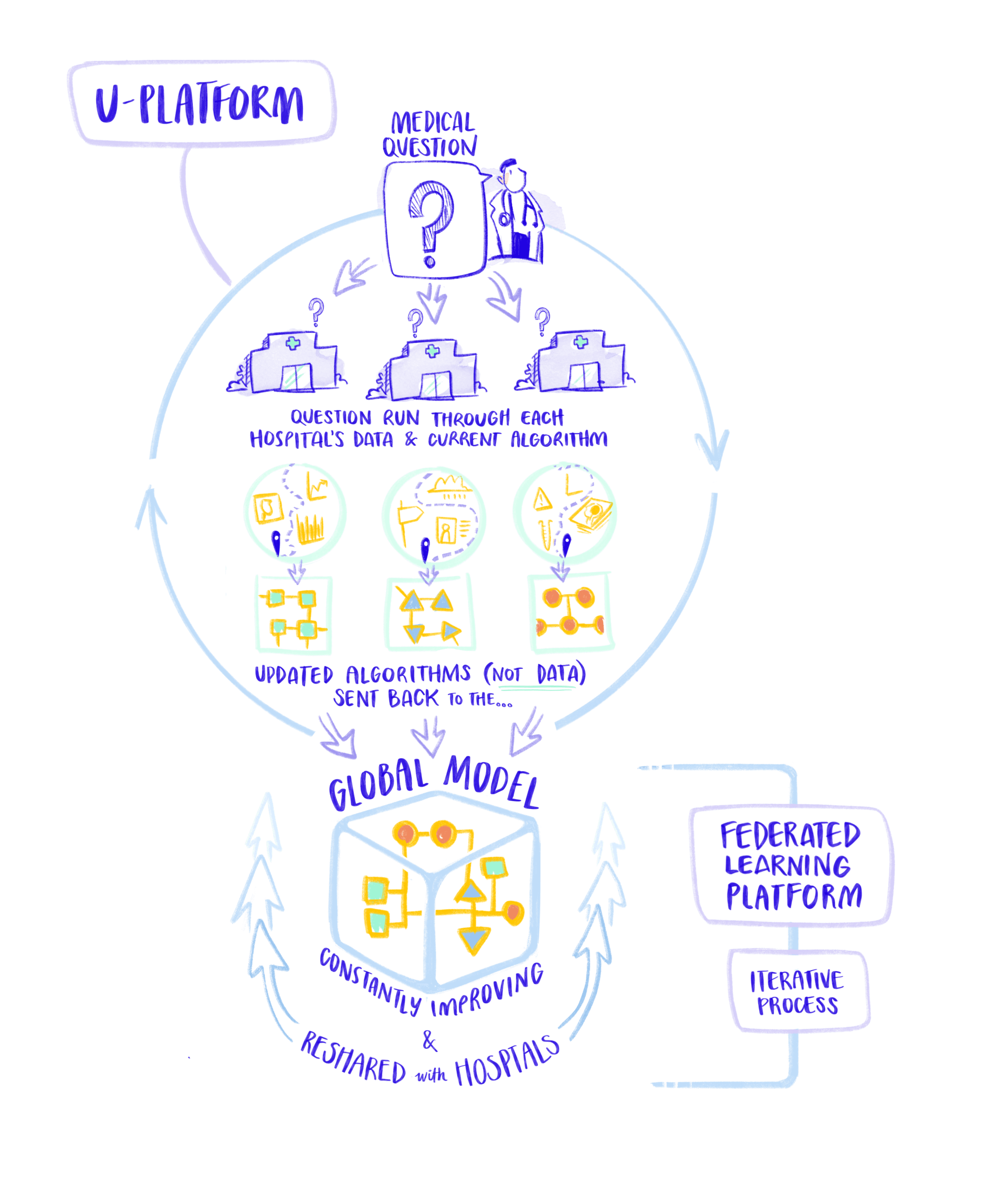
Federated learning provides a secure, decentralised solution to overcome the privacy and control challenges of centralised data approaches in healthcare.
To overcome these limitations, federated learning offers a secure and decentralised alternative. Instead of moving data, federated learning allows AI models to be trained where the data already exists. Each hospital keeps its patient data locally, behind its own secure systems, and only shares non‑identifiable model updates or aggregated results.
This approach significantly strengthens privacy protection, reduces the risk of cyberattacks, and ensures that each institution remains fully in control of its data. At the same time, it enables AI models to benefit from knowledge derived from many hospitals, making them more robust, accurate, and representative without requiring massive new infrastructure investments.
UMBRELLA uses local and federated learning platforms developed at Siemens Healthineers and CERN, respectively.
In UMBRELLA, federated learning is at the heart of the Analysis and Training step. A shared AI model blueprint is securely sent to participating hospitals, where it is trained locally using patient data that never leaves the hospital. The resulting model updates are then securely combined to improve the global model, without exposing any personal information.
This process is supported by strong security measures, including encryption, secure private connections, firewalls, and tightly controlled access. Crucially, the entire process is human‑supervised: clinicians, data scientists, and other experts continuously monitor, validate, and interpret the models. This ensures the system is transparent rather than a “black box”, ethical standards are upheld, and AI remains a tool that supports — not replaces — clinical judgement.
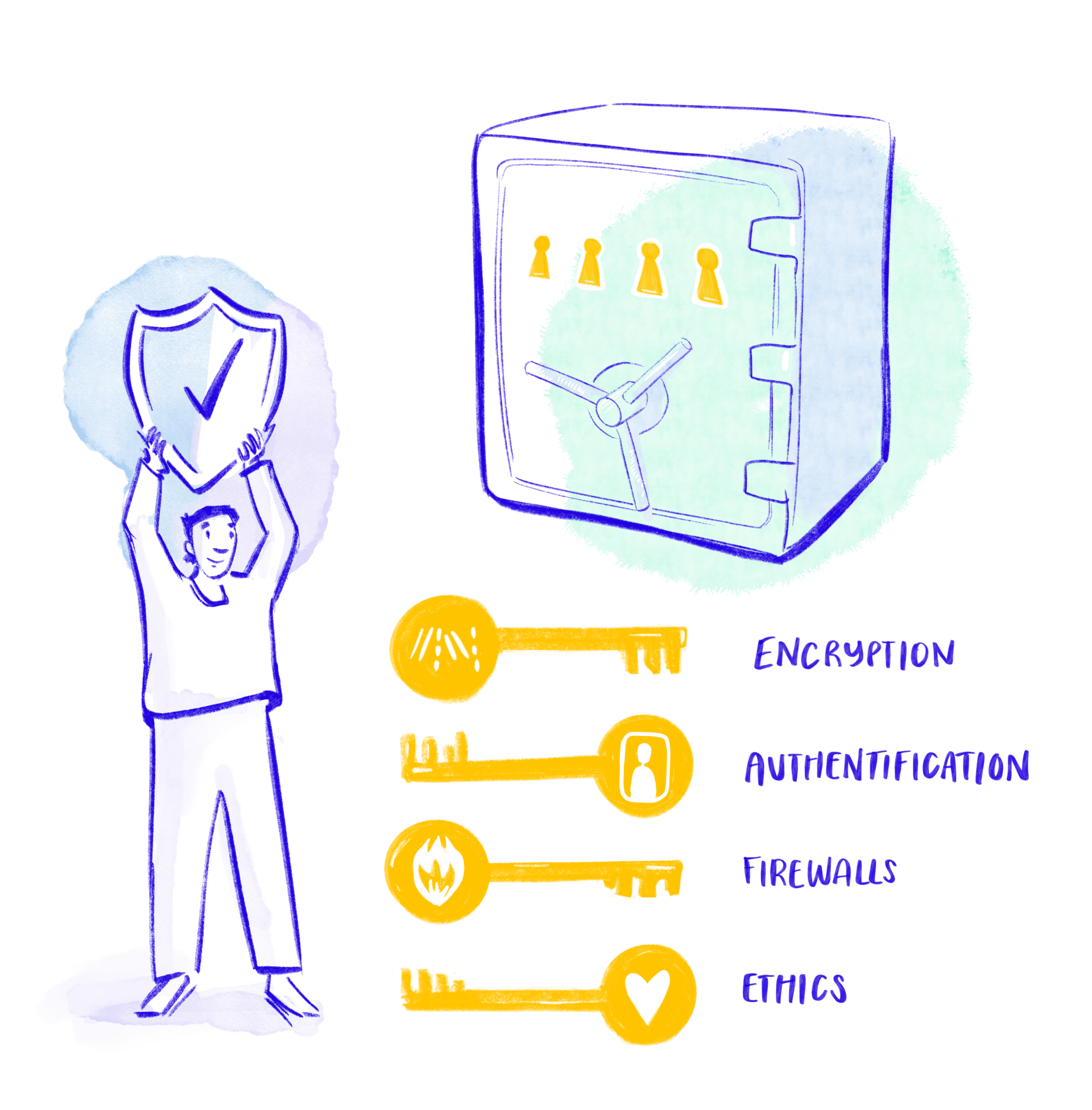

Privacy and security in UMBRELLA
Protecting patient data is paramount. There’s always a risk that hackers might try to intercept information or even reverse-engineer models to get sensitive details. To keep data safe, UMBRELLA uses strong encryption, multifactor authentication, and robust firewalls. All data travels through secure private tunnels, never over the public internet. On top of that, CERN’s team ensures the federated server is locked down and isolated. Local hospital servers also have extra layers of protection to guard against outside attacks and keep the models safe from manipulation.
Name Surname
TBC
While federated learning offers significant advantages in safeguarding privacy and harnessing collective intelligence, it also presents a unique set of challenges. For instance, bringing together hospital data for federated learning is no easy feat, with each site recording information in its own style. On top of that, since researchers never see the raw data, it’s tricky for them to assess how well the AI models are really performing across all locations. Also, it is not always clear how the global model was built, leading to questions about transparency and accountability. Finally, keeping the system running requires teams to harmonise data and maintain the underlying infrastructure at every hospital involved.
In UMBRELLA, close collaboration within a secure and controlled environment is proving essential to identify and develop practical, long-term solutions to address these general challenges.
Name Surname
TBC
Ethics in the loop: safeguarding fairness and transparency
Every patient-centred study must uphold rigorous ethical standards, with mandatory review and approval by an independent Ethics Committee before any research begins. These committees play a vital role in ensuring that patients are treated fairly, that there are no biases based on gender, ethnicity, age, or other characteristics, and that the research process remains fully transparent.
The rise of AI in healthcare introduces fresh ethical challenges: algorithms can inadvertently perpetuate bias if not carefully managed. To address this, the UMBRELLA project employs an iterative approach, where developers and researchers proactively identify and correct algorithmic errors, continually refining systems to minimise bias. Crucially, AI is designed to support—not supplant—clinical judgement, helping healthcare professionals work more efficiently and spot medical issues that might otherwise be missed. UMBRELLA’s Multistakeholder Advisory Board, comprising a reputable group of international experts, guarantees that robust ethical standards are followed throughout every stage of the process.
Name Surname
TBC

STEP 5 - EVALUATION
Testing model performance
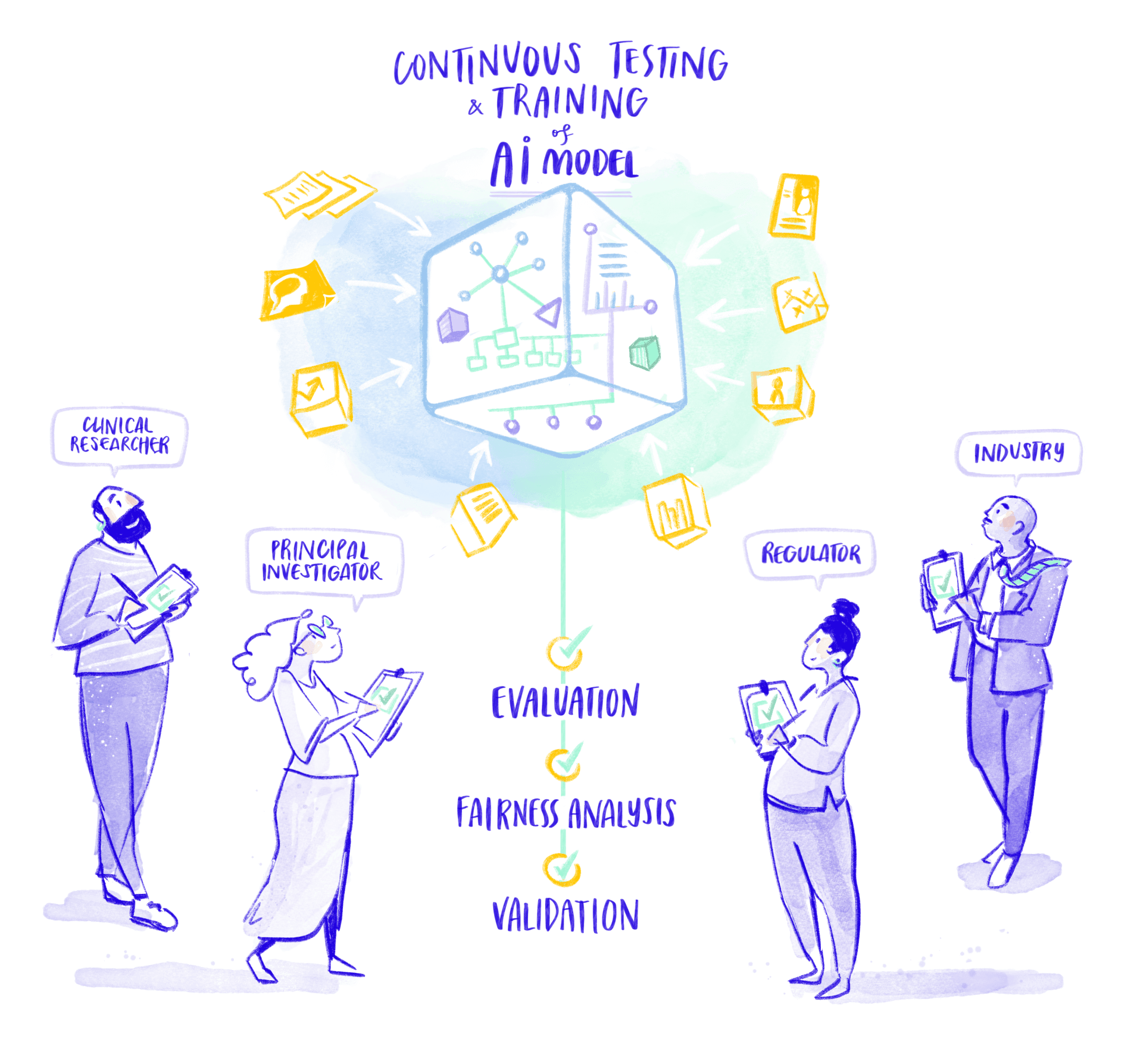
One of the most crucial stages in the AI lifecycle is verifying that the model works as it should and delivers accurate, dependable results across a wide range of patient groups and clinical scenarios. This includes systematically identifying and addressing any biases through a structured, iterative evaluation process. In UMBRELLA, this process is broken down into three distinct phases: technical validation, which examines the model’s performance against established metrics; clinical validation, where the model is tested in real-world healthcare settings; and impact evaluation, assessing its outcomes compared to current standards of care, described in stage 6 of the diagram. Implementing this comprehensive approach is complex, but it is essential for ensuring the AI’s effectiveness, fairness, and trustworthiness.
Technical validation
This key step evaluates the AI model’s performance against clinically relevant benchmarks. Much like products rolling along a factory conveyor belt in a factory, the model is continuously monitored at key stages for defects or inconsistencies. Metrics such as sensitivity, specificity, and accuracy are measured to determine whether the AI reliably detects important data patterns and performs effectively beyond its initial training. This process also doubles as ongoing
quality control, embedding transparency and spotlighting potential biases throughout the AI’s development lifecycle.
Clinical AI validation
Once the technical side of the AI model has been thoroughly checked, the real test begins—seeing how it performs in the day-to-day world of healthcare. Thanks to the federated FL-platform, each hospital gets to try out the AI model using its own patient data, without sharing sensitive patient information. The process uses reader studies, where clinicians examine stroke cases both with and without AI support. This helps reveal whether the AI improves accuracy, boosts confidence in diagnoses, or speeds up decisions. Each hospital then sends its findings to a central hub, where all the results are brought together. Because hospitals differ in their patient populations, equipment, and care routines, this federated approach gives a true picture of how the AI performs across a range of real-world settings.
This approach strengthens the credibility of clinical results by blending three key elements:
Checking how the AI performs in
real-life settings at each hospital.
Building consensus among
different hospitals through
joint reader studies
By combining federated validation and federated reader studies, this approach stands out as one of the most reliable and regulation-friendly ways to show that medical AI is safe, dependable, and works well in a wide variety of clinical environments.
Regulatory readiness: ensuring compliance from day one
Embedding regulatory requirements from the outset is crucial when developing medical technologies, especially those involving artificial intelligence (AI). European legislation such as the General Data Protection Regulation (GDPR) ensures that data privacy and safety are maintained throughout research and development. Additionally, the Medical Devices Regulation (MDR), the In Vitro Diagnostic Regulation (IVDR), and the recently approved Artificial Intelligence Act (AI Act) lay out strict standards for medical devices and high-risk AI systems. These laws require that any tool used for diagnosis, treatment, or disease prevention—including software that makes clinical decisions—must undergo thorough scrutiny and receive CE marking before being used in clinical practice.
Name Surname
TBC
UMBRELLA provides a clear example of how regulatory considerations can be woven into every stage of innovation
Rather than treating regulation as an afterthought, UMBRELLA makes it a core part of the process from day one. From the way data is gathered to how AI models are trained, tested, and evaluated, each step is guided by European regulations and internationally recognised standards like ISO 13485 for quality management. This proactive approach helps ensure that AI-based medical tools not only meet legal requirements but also pave the way for smooth clinical adoption, avoiding the delays and setbacks that often plague promising new technologies. Furthermore, the experience and knowledge gained through UMBRELLA will contribute to shaping future regulations, particularly in the fast-evolving field of AI in healthcare.
STEP 6 - IMPACT
Assessing AI outcomes and benefits
The impact evaluation basically establishes if the implementation of AI models in clinical settings make a difference for the better in terms of social, medical and economic costs. This evaluation is done under a health economics perspective, where UMBRELLA’s solutions are directly compared with today’s standard care. It tracks everything that matters— from clinical results and patient safety to costs and operational details— so experts can assess whether the new technology is better value for money.
This means watching out not just for health outcomes, but also for things like treatment delays, unnecessary hospital stays or readmissions, how long patients spend in hospital, and how much healthcare resources are used overall. To do this, hospitals working with UMBRELLA will help clearly spell out what counts as the current gold standard. Together with health economic experts, they will decide which comparisons matter most and which impact measures to focus on. By gathering this information in a structured way, UMBRELLA will produce solid evidence to help policymakers and health professionals figure out if—and where—these AI tools should be rolled out more widely.
Name Surname
TBC
Illustrations by Blanche Illustrates
Content by Gisela Pairó (Teamit), Anastasia Kuhfuss (Siemens Healthineers), Estela Sanjuan (VHIR), Anna Scott (SAFE), Luigi Serio (CERN), Ruud Selles (Erasmus University Medical Center), María Pin Nó (Teamit), Raghavan Ashok (Siemens Healthineers), Diogo Reis Santos (CERN), Carolina Migliorelli (Fundació Eurecat), Richard Warren (CERN), Leonhard Rist (Siemens Healthineers), Miguel Angel Souto (Idibell), Cristiana Costa (Instituto Pedro Nunes), Freya Sentmartí (Teamit), Alba Blasco (Teamit).
Web development by Nacar Design